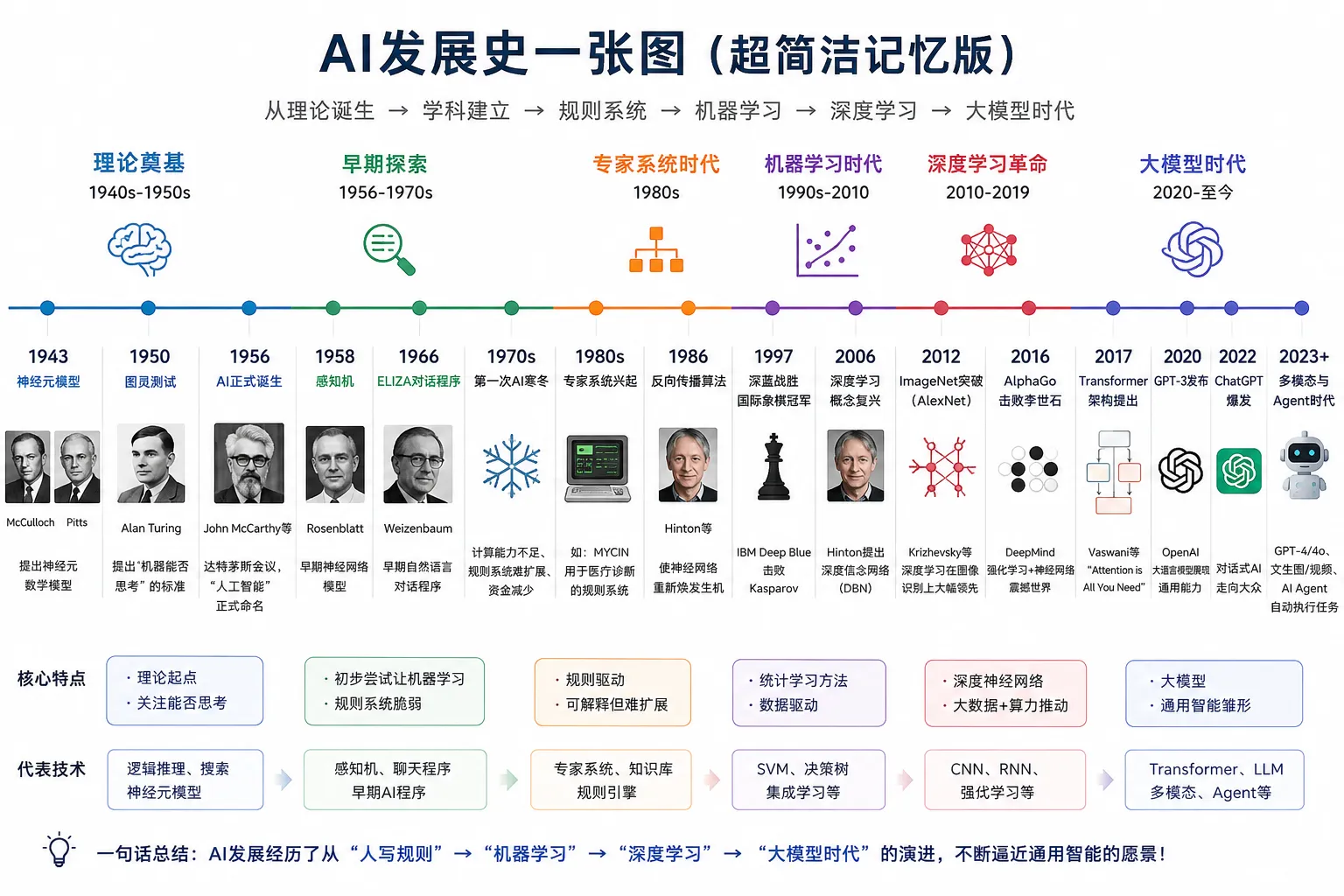
重要人物 & 重要事件
| 时间 | 人物 | 重要事件 | 时代背景 | 相关论文 |
|---|---|---|---|---|
| 1943 | * 沃伦·麦卡洛克(Warren McCulloch) * 沃尔特·皮茨(Walter Pitts) |
提出人工神经元模型,被视为神经网络的起点。 | 二战期间,信号处理、自动控制、数理逻辑快速发展,学界开始尝试用数学模型模拟人脑神经活动。 | A logical calculus of the ideas immanent in nervous activity |
| 1950 | 艾伦·图灵(Alan Turing) | 发表《计算机器与智能》,提出“图灵测试”。 | 第一台通用电子计算机问世不久,计算机能力初步显现,学界开始探讨机器是否具备“智能”。 | Computing Machinery and Intelligence |
| 1956 | * 约翰·麦卡锡(John McCarthy) * 马文·明斯基(Marvin Minsky) |
达特茅斯会议正式提出“Artificial Intelligence(人工智能)”这一名称。 | 计算机、逻辑学、神经科学交叉发展,一众学者希望合力打造具备人类思维能力的机器,AI 学科正式诞生。 | (会议论文集,无单一标题) |
| 1957 | 弗兰克·罗森布拉特(Frank Rosenblatt) | 发明感知机(Perceptron),推动早期神经网络研究。 | 人工智能处于发展初期,受MP神经元模型启发,研究者尝试搭建可自主学习的简易人工神经网络。 | The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain(1958正式发表) |
| 1966 | 约瑟夫·魏泽鲍姆(Joseph Weizenbaum) | 开发聊天程序 ELIZA,展示了人机对话的潜力。 | 早期AI聚焦自然语言交互,受限于技术,仅能依靠关键词匹配实现简单对话,是人机交互的初步探索。 | ELIZA — A Computer Program For the Study of Natural Language Communication Between Man and Machine |
| 1974–1980 | —— | 第一次“AI 寒冬”,由于算力和数据不足,研究热度下降。 | 硬件算力薄弱、算法局限性凸显,早期AI无法落地复杂场景,政府与资本削减科研经费,研究陷入停滞。 | —— |
| 1980年代 | 爱德华·费根鲍姆(Edward Feigenbaum) | 专家系统兴起,AI 开始在商业领域应用。 | 学界转向实用化方向,依托行业知识库打造专用AI系统,在医疗、工业、金融等领域落地,迎来短期复苏。 | The Fifth Generation: Artificial Intelligence and Japan’s Computer Challenge to the World(1983) |
| 1986 | * 杰弗里·辛顿(Geoffrey Hinton) * 大卫·鲁梅尔哈特(David Rumelhart) |
推广反向传播算法,使多层神经网络训练成为可能。 | 单层感知机缺陷明显,多层网络难以训练,反向传播算法突破这一瓶颈,为深度网络发展打下算法基础。 | Learning representations by back-propagating errors |
| 1997 | IBM Deep Blue 团队 | “深蓝”击败国际象棋世界冠军卡斯帕罗夫,AI 首次在复杂博弈中战胜人类顶尖选手。 | 计算机硬件性能大幅提升,算力足以支撑大规模穷举搜索,AI 在规则明确的博弈领域实现重大突破。 | Deep Blue: An Artificial Intelligence Chess System |
| 2006 | 杰弗里·辛顿(Geoffrey Hinton) | 提出深度信念网络(DBN)等方法,“深度学习”概念重新兴起。 | 传统浅层机器学习遇到性能天花板,辛顿解决了深度网络训练的梯度消失问题,唤醒沉寂多年的神经网络研究。 | A Fast Learning Algorithm for Deep Belief Nets |
| 2012 | * 亚历克斯·克里热夫斯基(Alex Krizhevsky) * 杰弗里·辛顿(Geoffrey Hinton) |
AlexNet 在 ImageNet 竞赛中大幅领先,深度学习进入主流。 | 互联网积累海量图像数据,GPU 并行计算普及,深度学习在视觉任务上碾压传统算法,行业全面转向深度模型。 | ImageNet Classification with Deep Convolutional Neural Networks |
| 2014 | 伊恩·古德费洛(Ian Goodfellow) | 提出生成对抗网络(GAN),推动生成式 AI 发展。 | 判别式模型日趋成熟,学界开始探索机器“创作”能力,GAN 利用对抗思想大幅提升图像、文本生成效果。 | Generative Adversarial Nets |
| 2016 | DeepMind 团队(Demis Hassabis 等) | AlphaGo 战胜围棋冠军李世石,震动全球。 | 围棋规则复杂、组合无穷,传统搜索算法难以胜任,AlphaGo 结合深度学习与强化学习,打破大众对AI能力的认知。 | Mastering the game of Go with deep neural networks and tree search |
| 2017 | Vaswani 等 Google 研究者 | 发表《Attention Is All You Need》,提出 Transformer 架构,奠定现代大模型基础。 | 循环神经网络处理长文本效率低,注意力机制被提出,Transformer 架构适配并行计算,成为自然语言处理核心框架。 | Attention Is All You Need |
| 2018 | OpenAI 团队 | 发布 GPT,展示大规模语言模型的潜力。 | Transformer 架构成熟,互联网海量文本数据可用于预训练,大参数语言模型开始展现强大的语言理解与生成能力。 | Improving Language Understanding by Generative Pre-Training |
| 2020 | OpenAI 团队 | 发布 GPT-3,参数规模和生成能力大幅提升。 | 算力集群、大数据、预训练技术全面成熟,行业开始走向超大规模参数模型路线,通用人工智能初见雏形。 | *Language Models are Few-Shot Learners |
| 2022 | OpenAI 团队 | ChatGPT 发布,生成式 AI 进入大众视野。 | 对话优化、指令微调技术落地,大模型交互体验大幅提升,AI 从科研、产业走向普通用户。 | Training Language Models to Follow Instructions with Human Feedback(InstructGPT,ChatGPT核心技术) |
| 2023 | OpenAI、Anthropic、Google DeepMind 等 | 大模型竞赛加速,GPT-4、Claude、Gemini 等模型推动 AI 应用爆发。 | 全球科技企业争相布局通用大模型,技术快速迭代,AI 渗透办公、创作、工业、生活等全场景。 | GPT-4 Technical Report(OpenAI) Claude 2 Technical Overview(Anthropic) Gemini: A Family of Highly Capable Multimodal Models(Google) |
里程碑
1 | AI |
第一阶段:规则时代(1950s~1980s)
做法,专家告诉机器规则:
1 | 如果发烧 && 咳嗽 |
例如:
专家系统
规则引擎
问题,现实世界太复杂。
例如识别猫:
1 | 什么耳朵算猫? |
规则写不完。于是进入
1 | AI |
第二阶段:机器学习时代(1980s~2010)
核心思想:不写规则,让机器从数据中学习规则。
例如:
1 | 给机器 |
问题,人还得手工提特征。例如:
1 | 耳朵长度 |
工程师必须告诉模型:哪些特征重要,于是进入
1 | Machine Learning |
第三阶段:深度学习时代(2012)
代表事件:AlexNet,核心思想:特征也让机器自己学。
以前:
1 | 人工找特征 |
现在:
1 | 原始数据 |
例如猫:机器自动学会:
1 | 第一层 |
成果,图像识别爆炸式提升。于是:CNN时代,开始了。
第四阶段:CNN与RNN分家
因为数据类型不同。
CNN适合图片
1 | 像素 |
局部特征最重要。
RNN适合文本
1 | 我 |
需要记忆前文。
问题:RNN有致命缺陷。例如:
1 | 我出生于北京, |
RNN早忘了。于是进入
1 | RNN |
第五阶段:Transformer革命(2017)
论文:Attention Is All You Need,核心创新:Attention(注意力机制)。以前RNN:一个词一个词读,像看书:
1 | 第一页 |
不能回头。Transformer:所有词同时看,例如:
1 | The animal didn't cross the street |
而不是靠记忆。优势:
- 并行计算
- 长距离依赖
- GPU友好
于是:
1 | Transformer |
第六阶段:大模型(LLM)
大家突然发现:Transformer越大越聪明。参数增长:
1 | 1亿 |
数据增长:
1 | 一本书 |
出现了所谓:
1 | LLM |
为什么ChatGPT会出现?关键发现(Scaling Law):Scaling Laws 指出:
1 | 模型更大 |
不是突然发明了新算法。而是:Transformer不断放大,产生了涌现能力:
- 对话
- 写代码
- 推理
- 翻译
- 创作